네이버 금융 테마별 시세 페이지 목록 스크래핑을 해보자!

앞선 업종별 시세와 다르게, 테마별 시세는 테이블이 여러 페이지로 구분되어 있다. 따라서 함수와 반복문을 활용하여 여러 페이지 수집이 가능하게 구현해야 한다.
업종별 시세 페이지 스크래핑과 마찬가지로,
테마별 시세 페이지 스크래핑도 1) 목록 수집 2) 각 업종의 내용 수집, 두 단계로 진행한다.
이번 포스팅에서는 목록 수집만!
3-1. 테마별 시세 페이지 스크래핑-목록
1. 필요 라이브러리 로드
2. 수집할 페이지 URL 설정
3. requests 요청
4. table 정보 확인 + 간단한 전처리
5. BeautifulSoup으로 html parsing
6. 테마별(목록) 링크 태그 찾기 + 목록별 링크 번호만 가져오기
7. 2)~6) 과정 함수로 만들기
8. 반복문으로 여러 페이지 데이터 가져오기
9. 하나의 데이터프레임 병합 + 파일 저장
1) 필요 라이브러리 로드
# 라이브러리 로드
import time
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup as bs2) 수집할 페이지 URL 설정
# url 설정
page_no = 1
url = f"https://finance.naver.com/sise/theme.naver?&page={page_no}"
print(url)네이버 증권 테마별 시세 페이지 URL을 url 변수에 넣어준다. 페이지를 넘길 때마다 바뀌는 링크 부분을 보고 fstring 처리 해준다.
3) requests 요청
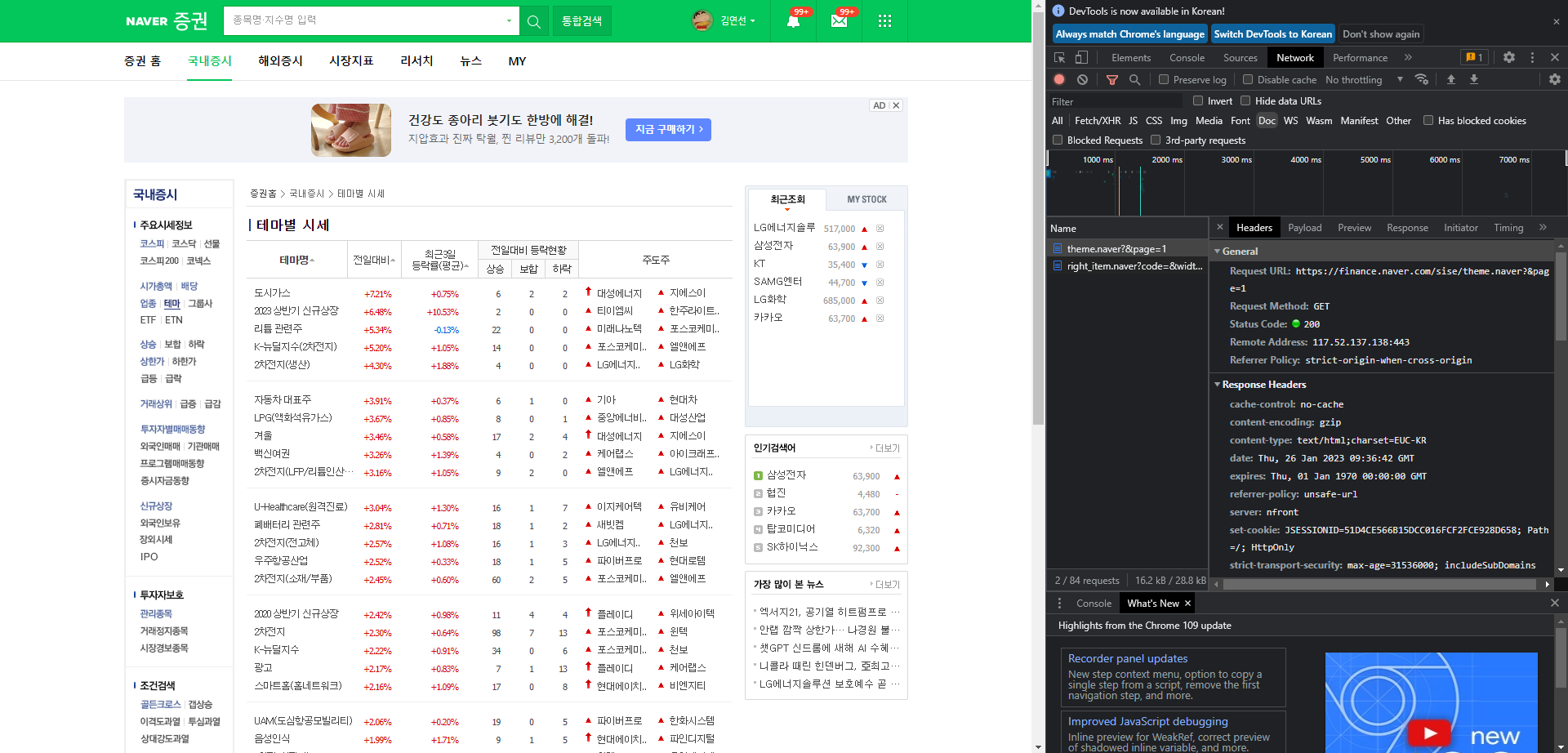
테마별 시세 페이지 역시 GET 방식을 사용하고 있음을 알 수 있다.
# requests 요청
response = requests.get(url)
response.status_code200이 출력되면 ok
4) table 정보 확인 + 간단한 전처리
# table 정보 확인
table = pd.read_html(response.text)[0]
tablepd.read_html로 테마별 시세 테이블을 확인해보면

간단한 전처리가 필요해보인다.
# 전처리
# 결측치 제거
table = table.dropna()
# 인덱스 초기화
table = table.reset_index(drop=True)
# 컬럼명 변경
table.columns = ['테마명', '전일대비', '최근3일등락률(평균)' ,'전일대비 등락현황(상승)', '전일대비 등락현황(보합)', '전일대비 등락현황(하락)', '주도주1', '주도주2']
table
결측치 제거, 인덱스 초기화, 컬럼명 변경까지 해준다.
5) BeautifulSoup으로 html parsing
html 파싱을 위해 BeautifulSoup을 활용한다.
# BeautifulSoup으로 html parsing
html = bs(response.text)
html
6) 테마별(목록) 링크 태그 찾기 + 목록별 링크 번호만 가져오기

# 테마별 링크 태그 찾기
# #contentarea_left > table.type_1.theme > tbody > tr:nth-child(4) > td.col_type1 > a
link_list = html.select("table.type_1.theme > tr > td.col_type1 > a")
link_list.select()로 테마별 링크 태그만 link_list 변수에 담아준다. 하나의 링크만이 아닌 테마별 시세 리스트 전체의 링크 태그를 가져와야 하므로 nth-child 같은 것은 지워준다.

# 링크 태그 no만 가져오기
link_list_no = [a["href"].split("=")[-1] for a in link_list]
link_list_nolist comprehension으로 앞서 구한 링크 태그 중 번호만 가져와 link_list_no 변수에 담는다.

# 데이터 프레임에 링크 번호 추가하기
table["링크번호"] = link_list_no
table기존 전처리한 데이터프레임에 "링크번호" 컬럼과 뽑아둔 링크번호 값을 추가한다.

# 테마명과 링크번호가 일치하는지 확인
theme_url = f"https://finance.naver.com/sise/sise_group_detail.naver?type=theme&no="
link_no = 2
print(table["테마명"][link_no])
print(theme_url + table["링크번호"][link_no])오와열이 잘 맞게 들어갔는지 확인해본다...

확인해보면 잘 들어감
7) 2)~6) 과정 함수로 만들기
그럼 이제 위 과정을 하나의 함수로 만들어보자. (왜냐면 여러 페이지를 수집해야 하기 때문)
# 여러 페이지 수집을 위해 위 과정 함수로 만들기
def get_a_page_theme(page_no):
'''
네이버 증권 테마별 시세 페이지 수집 함수
'''
# 1) url 설정
theme_url = f"https://finance.naver.com/sise/theme.naver?&page={page_no}"
# 2) requests 요청
page_response = requests.get(theme_url)
# 3) table 정보 불러오기
theme_table = pd.read_html(page_response.text)[0]
# 결측치 제거
theme_table = theme_table.dropna()
# 인덱스 초기화
theme_table = theme_table.reset_index(drop=True)
# 컬럼명 변경
theme_table.columns = ['테마명', '전일대비', '최근3일등락률(평균)' ,'전일대비 등락현황(상승)', '전일대비 등락현황(보합)', '전일대비 등락현황(하락)', '주도주1', '주도주2']
# 4) bs 형태로 만들기
theme_html = bs(page_response.text)
# 5) 테마별 링크 태그 찾기
theme_link_list = theme_html.select("table.type_1.theme > tr > td.col_type1 > a")
# 6) 링크 태그 no만 가져오기
theme_link_list_no = [a["href"].split("=")[-1] for a in theme_link_list]
# 7) table에 "링크번호" 컬럼 추가
theme_table["링크번호"] = theme_link_list_no
# 8) table 반환
return theme_table변수명이 조금 다르니 주의
예외처리는 안 해주었는데, 테마별 시세 페이지는 총 7페이지로, 변하지 않기 때문이다.(아마도)
+ page_no에 100을 해줘도 마지막 페이지인 7페이지가 정상적(?)으로 나와 조금 이상함
# 함수 작동 확인
a = get_a_page_theme(1)
a함수가 잘 작동하는지 확인해보면

1페이지를 정상적으로 잘 가져왔다. (39rows)
8) 반복문으로 여러 페이지 데이터 가져오기
# 반복문으로 모든 페이지 가져오기
result = []
for i in range(1,8):
table = get_a_page_theme(i)
result.append(table)
result이제 위에서 만든 함수와 반복문을 이용해서 테마별 시세의 7페이지를 모두 가져와보자.이때 리스트로 만들고 .append()하여 페이지를 덧붙여준다.

요렇게 리스트 형식으로 만듦
9) 하나의 데이터프레임 병합 + 파일 저장
이제 마지막! pd.concat()으로 하나의 데이터프레임으로 만들어보자.
# 하나의 데이터프레임으로 병합
df = pd.concat(result, ignore_index=True)
df
인덱스 초기화 해주면 요렇게 쭉 붙음. 히히
# 파일로 저장
file_name = "naver-finance-theme-list.csv"
df.to_csv(file_name, index=False)csv 파일로 저장해봅시다.
pd.read_csv(file_name)
잘 저장됐지요?
테마별 시세 페이지 목록 수집은 끝! 여기서 만든 파일을 바탕으로 각 테마의 종목(내용)을 수집할 예정.
다음 포스팅 : 테마별 시세 페이지 내용(종목) 스크래핑
'Data Project > Mini Project1' 카테고리의 다른 글
| 네이버 금융 웹페이지 스크래핑 0302테마스크래핑-내용 (0) | 2023.01.26 |
|---|---|
| 네이버 금융 웹페이지 스크래핑 0202업종스크래핑-내용 (0) | 2023.01.24 |
| 네이버 금융 웹페이지 스크래핑 0201업종스크래핑-목록 (0) | 2023.01.21 |
| 네이버 금융 웹페이지 스크래핑 01시작하기 (0) | 2023.01.21 |



